2022. 12. 13. 21:00 수정 및 복습 시작
데이터 모델
데이터 모델은 데이터 구조, 연산, 제약조건으로 구성된다.
관계 데이터 모델에서 연산은 원하는 데이터를 얻기 위해 릴레이션에 필요한 처리 요구를 수행하는 것으로,
데이터베이스 시스템의 구성 요소 중 데이터 언어의 역할을 한다.
관계 데이터 모델의 연산을 간단히 관계 데이터 연산이라고도 한다.
관계 데이터 연산
대표적인 관계 데이터 연산으로 관계 대수와 관계 해석이 있다.
관계 대수와 관계 해석은 원하는 데이터를 얻기 위한 처리 절차를 얼마나 자세히 기술하느냐에서 큰 차리를 보인다.
- 관계 대수: 원하는 결과를 얻기 위해 데이터의 처리 과정을 순서대로 기술하는 절차 언어다.
- 관계 해석: 관계 해석은 원하는 결과를 얻기 위해 처리를 원하는 데이터가 무엇인지만 기술하는 비절차 언어다.
관계 해석이 더 친절해 보이지만 데이터를 처리하는 기능과 처리를 요구하는 표현력에서 관계 대수와 관계 해석은 능력이 동등하다.
관계 대수와 관계 해석의 역할은 데이터 언어의 유용성을 검증해야 하는 기준이다.
관계 대수나 관계 해석으로 기술할 수 있는 모든 질의를 새로 제안된 데이터 언어로 기술할 수 있으면 관계적으로 완전하다고 하고,
이를 통해 해당 언어가 어느 정도 검증됐다고 판단한다.
데이터에 대한 처리 요구를 일반적으로 질의-query라고 한다. 따라서 앞으로는 쿼리라는 용어를 사용하겠다.
관계 대수
이제 관계 대수에 대해 더 자세히 알아보겠다. 관계 해석은 개념만 살짝 알아보겠다.
관계 대수는 원하는 결과를 얻기 위해 릴레이션을 처리하는 과정을 순서대로 기술하는 언어다.
연산자들의 집합으로도 정의할 수 있다.
일반적으로 연산자와 함께 연산의 대상이 되는 피연산자가 존재하기 마련인데 관계 대수에서는 피연산자가 릴레이션이다.
즉, 관계 대수는 릴레이션을 연산한다. 피연산자인 릴레이션에 연산자를 적용해 얻은 결과도 릴레이션이다.
이러한 관계 대수의 특성을 폐쇄 특성이라 하는데, 이는 '콩 심은 데 콩 나고 팥 심은 데 팥 난다'라는 속담을 떠올리게 한다.
관계 대수에 속하는 대표적인 연산자 8개는 특성에 따라 일반 집합 연산자와 순수 관계 연산자로 분류할 수 있다.
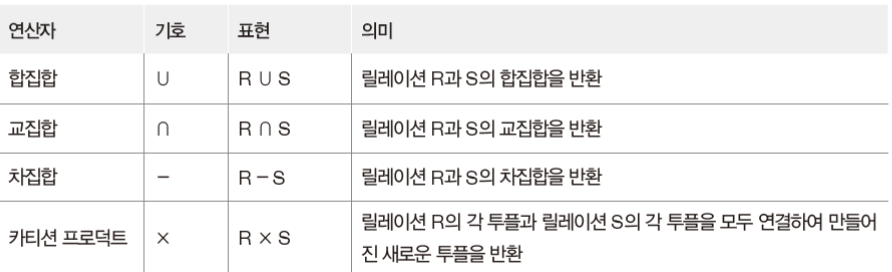
- 일반 집합 연산자: 합집합, 교집합, 차집합, 카티션 프로덕트
- 순수 관계 연산자: 셀렉트, 프로젝트, 조인, 디비전
일반 집합 연산자
일반 집합 연산자는 릴레이션이 투플의 집합이라는 개념을 이용했다.
일반 집합 연산자는 2개의 특성이 있다.
- 피연산자가 2개 필요하다. 2개의 릴레이션을 대상으로 연산을 수행한다.
- 합집합, 교집합, 차지합은 피연산자인 2개의 릴레이션이 합병 가능해야 한다.
합병 가능 조건은 두 릴레이션의 차수가 같아야 한다. 즉 두 릴레이션은 속성 개수가 같다.
2개의 릴레이션에서 서로 대응되는 속성의 도메인이 같다. 단 도메인이 같으면 속성의 이름은 달라도 된다.
합집합
- 합병 가능 한 두 릴레이션 R과 S의 합집합 : R∪S이다.
- 릴레이션 R에 속하거나 릴레이션 S에 속하는 모든 투플로 결과 릴레이션을 구성한다.
- 결과 릴레이션의 특성은 차수는 릴레이션 R과 S의 차수와 같다.
- 카디널리티는 릴레이션 R과 S의 카디널리티를 더한 것과 같거나 작아진다.
- 교환적 특징이 있으며 결합적 특징이 있다.
교집합
- 합병 가능한 두 릴레이션의 R과 S의 교집합 : R∩S이다.
- 릴레이션 R과 S에 공통으로 속하는 투플로 결과 릴레이션을 구성한다.
- 결과 릴레이션의 특성은 차수는 릴레이션 R과 S의 차수와 같다.
- 카디널리티는 R과 S의 어떤 카디널리티보다 크지 않다.
- 교환적 특징이 있으며 결합적 특징이 있다.
차집합
- 합병 가능한 두 릴레이션의 R과 S의 차집합 : R-S이다.
- 릴레이션 R에는 존재하지만 릴레이션 R에는 존재하지 않는 투플로 결과 릴레이션을 구성한다.
- 결과 릴레이션의 특성은 차수는 릴레이션 R과 S의 차수와 같다.
- R-S의 카디널리티는 릴레이션 R의 카디널리티와 같거나 적다.
- S-R의 카디널리티는 릴레이션 S의 카디널리티와 같거나 적다.
- 교환적, 결합적 특징이 없다.
카티션-프로덕트
- 두 릴레이션 R과 S의 카티션 프로덕트 : R X S이다.
- 릴레이션 R에 속한 투플과 릴레이션 S에 속한 각 투플을 모두 연결하여 만들어진 새로운 투플로 결과 릴레이션을 구성결과 릴레이션의 특징은 차수는 릴레이션 R과 S의 차수를 더한 것과 같다.
- 카디널리티는 릴레이션 R과 S의 카디널리티를 곱한 것과 같다.
- 교환적 특징과 결합적 특징이 있다.

순수 관계 연산자
순수 관계 연산자는 릴레이션의 구조와 특성을 이용하는 연산자다.
대표적으로 셀렉트, 프로젝트, 조인 ,디비전이 있다.
셀렉트
- 릴레이션에서 조건을 만족하는 투플만 선택하여 결과 릴레이션을 구성한다.
- 하나의 릴레이션을 대상으로 연산을 수행한다.
- 수학적 표현법은 σ조건식 (릴레이션)이다. 그리스 알파벳 시그마라고 알아두면 되겠다.
- 데이터 언어적 표현법은 릴레이션 where 조건식이다.
- 조건식은 비교식, 프레디 킷이라고도 한다. 속성과 상수의 비교나 속성들 간의 비교로 표현한다.
- 비교 연산자와 논리 연산자를 이용해 작성한다.
프로젝트
- 릴레이션에서 선택한 속성의 값으로 결과 릴레이션을 구성한다.
- 하나의 릴레이션을 대상으로 연산을 수행한다.
- 수학적 표현법은 π속성 리스트(릴레이션)이다.
- 데이터 언어적 표현법은 릴레이션[속성 리스트[이다.
- 결과 릴레이션에서 동일한 투플은 중복되지 않고 한 번만 나타난다.
- 결과 릴레이션은 연산 대상 릴레이션의 수직적 부분집합이다.
조인(join)
- 조인 속성을 이용해 두 릴레이션을 조합하여 결과 릴레이션을 구성한다.
- 조인 속성의 값이 같은 투플만 연결하여 생성된 투플을 결과 릴레이션에 포함한다.
- 조인 속성은 두 릴레이션이 공통으로 가지고 있는 속성이다.
- 표현법은 릴레이션 1 ▷◁ 릴레이션 2이다.
- 자연 조인 (natural join)이라고도 한다.
세타 조인
- 자연 조인에 비해 더 일반화된 조인이다.
- 주어진 조건을 만족하는 두 릴레이션의 모든 투플을 연결하여 생성된 새로운 투플로 결과 릴레이션을 구성한다.
- 결과 릴레이션의 차수는 두 릴레이션의 차수를 더한 것과 같다.
- 표현법은 릴레이션 1 ▷◁(A 비교 연산자 B) 릴레이션 2이다.
- 동일 조인은 세타 조인과 동일하다만 표현법에서 A 비교 연산자 B에서 비교 연산자가 =인 세타 조인이다
디비전
- 표현법은 릴레이션 1 / 릴레이션 2이다.
- 릴레이션 2의 모든 투플과 관련이 있는 릴레이션 1의 투플로 결과 릴레이션을 구성한다.
- (단, 릴레이션 1이 릴레이션 2의 모든 속성을 포함하고 있어야 연산이 가능하다.)
- 즉 도메인이 같아야 한다는 의미다.
세미 조인
- 조인 속성으로 프로젝트 연산을 수행한 릴레이션을 이용하는 조인이다
- 릴레이션 2를 조인 속성으로 프로젝트 연산한 후, 릴레이션 1에 자연 조인하여 결과 릴레이션을 구성한다.
- 불필요한 속성을 미리 제거하여 조인 연산 비용을 줄이는 장점이 있다.
- 교환적 특징은 없다.
외부 조인
- 자연 조인 연산에서 제외되는 투플도 결과 릴레이션에 포함시키는 조인이다.
- 즉, 두 릴레이션에 있는 모든 투플을 결과 릴레이션에 포함시킨다.
관계 해석
관계 해석은 처리를 원하는 데이터가 무엇인지만 기술하는 언어이다. 비절차적 언어다.
수학의 프레디 킷 해석에 기반을 두고 있다.
이상 포스팅을 마칩니다.
2022. 12. 13. 22:00 수정 및 복습 마무리

